14.4 Обработка текстовых потоков (Processing Text Streams)¶
При обработке текстовых потоков внутри сценария или при передаче вывода через конвейер в командной строке бывают ситуации, когда необходимо отфильтровать вывод одной команды так, чтобы определённые части текстового потока действительно передавались на стандартный ввод следующей команды. Для этого можно использовать разнообразные инструменты. В заключительной части данной главы рассматривается применение следующих команд:
cutexpandиunexpandfmtjoinиpastenlodprsedиawksortsplittruniqwc
Начнём с команды cut.
cut¶
Команда cut используется для вывода на стандартный вывод указанных столбцов или полей из файла. По умолчанию в качестве разделителя используется символ табуляции. С командой cut можно использовать следующие параметры:
-blist— Выбрать только указанные байты.-clist— Выбрать только указанные символы.-ddelim— Использовать указанный символ вместо табуляции в качестве разделителя полей.-flist— Выбрать только указанные поля. Выводить строки, не содержащие символа-разделителя, если не задан параметр-s.-s— Не выводить строки, не содержащие разделителей.
Например, с помощью команды cut можно вывести все имена групп из файла /etc/group. Напомним, что имя каждой группы находится в первом поле каждой строки этого файла. Однако в файле групп в качестве разделителя между полями используются двоеточия, поэтому необходимо указать двоеточие вместо табуляции в качестве разделителя. Для этого служит команда cut -d: -f1 /etc/group. Пример показан на рис. 14-2.

Рис. 14-2. Использование команды cut для извлечения поля из /etc/group.
Рассмотрим далее команды expand и unexpand.
expand и unexpand¶
Команда expand используется для обработки текстового потока: она удаляет все символы табуляции и заменяет их указанным количеством пробелов (по умолчанию — восемью). Для задания другого количества пробелов можно использовать параметр -t число. Синтаксис: expand -t число имя_файла. На рис. 14-3 символы табуляции в файле tabfile заменены пятью пробелами.

Рис. 14-3. Использование expand для замены символов табуляции пробелами.
Можно также использовать команду unexpand. Команда unexpand работает в противоположном направлении по отношению к команде expand: она преобразует пробелы в текстовом потоке обратно в символы табуляции. По умолчанию восемь последовательных пробелов преобразуются в один символ табуляции. Для задания другого количества пробелов можно использовать параметр -t.
Важно отметить, что по умолчанию команда unexpand преобразует только пробелы в начале каждой строки. Чтобы принудительно преобразовать все пробелы нужного количества в символы табуляции, необходимо добавить к команде unexpand параметр -a. На рис. 14-4 пять пробелов в начале второй и третьей строк файла tabfile, созданных командой expand, преобразуются обратно в символы табуляции с помощью команды unexpand.

Рис. 14-4. Преобразование пробелов в символы табуляции с помощью команды unexpand.
Рассмотрим далее форматирование текста с помощью команды fmt.
fmt¶
Команда fmt используется для переформатирования текстового файла. Чаще всего её применяют для изменения переноса длинных строк в файле, чтобы привести их к более удобной ширине. Синтаксис команды fmt: fmt параметр имя_файла.
Например, с помощью параметра -w можно сузить текст файла до 80 столбцов, введя команду fmt -w 80 имя_файла. Пример показан на рис. 14-5.

Рис. 14-5. Использование fmt для изменения количества столбцов в текстовом файле.
Рассмотрим далее команды join и paste.
join и paste¶
Команда join выводит строку из каждого из двух указанных входных файлов, у которых совпадают поля объединения. По умолчанию полем объединения является первое поле, разделённое пробельным символом. Для указания другого поля объединения можно использовать параметр -j поле.
Например, предположим, что у вас есть два файла. Первый файл (с именем firstnames) содержит следующее:
Второй файл (с именем lastnames) содержит следующее:
Для объединения соответствующих строк из каждого файла можно выполнить команду join -j 1 firstnames lastnames. Пример показан ниже:
Команда paste работает примерно так же, как и команда join: она соединяет соответствующие строки из одного или нескольких файлов в столбцы. По умолчанию для разделения столбцов используется символ табуляции. Для задания другого символа-разделителя можно использовать параметр -dn. Также можно использовать параметр -s для вывода содержимого каждого файла в одну строку.
Например, с помощью команды paste можно объединить соответствующие строки из файлов firstnames и lastnames, введя команду paste firstnames lastnames. Пример показан ниже:
Рассмотрим далее команду nl.
nl¶
Команда nl определяет количество строк в файле. При выполнении команды в начало каждой строки файла добавляется её номер. Синтаксис: nl имя_файла.
Например, в следующем примере команда nl используется для добавления номера в начало каждой строки файла tabfile.txt:
rtracy@openSUSE:~> nl tabfile.txt
1 This file uses tabs.
2 This line used a tab.
3 This line used a tab.
4 After using expand, the tabs will be replaced with spaces.
od¶
Команда od (octal dump — восьмеричный дамп) используется для вывода дампа файла, в том числе двоичных файлов. Эта утилита позволяет формировать дамп в нескольких форматах: восьмеричном, десятичном, с плавающей точкой, шестнадцатеричном и символьном. Поскольку вывод команды od представляет собой обычный текст, для его дальнейшей фильтрации можно использовать другие инструменты обработки потоков.
Команда od может оказаться очень полезной. Например, с её помощью можно выполнить дамп файла, чтобы обнаружить в нём посторонние символы. Предположим, что сценарий был создан в редакторе другой операционной системы (например, Windows), а затем его попытались запустить в Linux. В зависимости от использованного редактора в тексте сценария могут присутствовать скрытые символы форматирования, которые не отображаются текстовым редактором. Однако оболочка bash прочитает их при попытке запустить сценарий, что вызовет ошибки. При просмотре сценария в редакторе всё выглядит нормально.
С помощью команды od можно просмотреть дамп сценария, чтобы определить, в каком месте файла находятся проблемные символы. Синтаксис команды od: od параметры имя_файла. Среди наиболее часто используемых параметров выделим следующие:
-b— Восьмеричный дамп.-d— Десятичный дамп.-x— Шестнадцатеричный дамп.-c— Символьный дамп.
Например, на рис. 14-6 простой сценарий «Hello World» создан в текстовом процессоре LibreOffice и сохранён в виде файла .odt. В результате в текст встроено множество скрытых символов.

Рис. 14-6. Создание сценария в LibreOffice.
Эти символы, очевидно, не видны в LibreOffice. Однако их можно просмотреть с помощью команды od -c helloworld.odt. Это показано на рис. 14-7.

Рис. 14-7. Создание символьного дампа с помощью od.
Рассмотрим далее команду pr.
pr¶
Команда pr используется для форматирования текстовых файлов перед печатью. Она форматирует файл с разбивкой на страницы, добавляет заголовки и столбцы. Заголовок содержит дату и время, имя файла и номер страницы. С командой pr можно использовать следующие параметры:
-d— Двойной интервал между строками вывода.-l длина_страницы— Установить длину страницы в указанное число строк. По умолчанию — 66.-o поля— Добавить отступ каждой строки на указанное число пробелов. По умолчанию поле равно 0.
Рассмотрим далее команды sed и awk.
sed и awk¶
Команда sed — это потоковый текстовый редактор (stream text editor). В отличие от интерактивных текстовых редакторов, изученных ранее в этой книге (например, vi), потоковый редактор принимает текстовый поток на стандартный ввод, выполняет над ним указанные операции, а затем sed отправляет результаты на стандартный вывод. С командой sed можно использовать следующие команды:
s— Заменяет вхождения указанной текстовой строки другой текстовой строкой. Синтаксис командыs:sed s/строка1/строка2/. Например, на рис. 14-8 с помощью командыcatотображается файлlipsum.txtв домашнем каталоге пользователяtux. Затемcatчитаетlipsum.txt, передаёт стандартный вывод на стандартный ввод командыsedи указывает заменить слово «ipsum» на «IPSUM».d— Удаляет указанный текст. Например, чтобы удалить каждую строку стандартного ввода, содержащую слово «eos», следует ввестиsed /eos/d.
Следует помнить, что команда sed не изменяет сам источник данных — в данном случае файл lipsum.txt. Она принимает стандартный ввод, вносит изменения и отправляет результат на стандартный вывод. Если необходимо сохранить изменения, внесённые командой sed, нужно перенаправить стандартный вывод в файл с помощью >. Например, вывод из команды на рис. 14-8 можно перенаправить в файл lipsum_out.txt, введя cat lipsum.txt | sed s/ipsum/IPSUM/ > lipsum_out.txt в командной строке.
Примечание
Команды sed и awk, рассматриваемые в данной главе, обладают весьма широкими возможностями. Здесь мы охватываем только основы, необходимые для экзамена Linux+/LPIC-1. Рекомендуется изучить man-страницы обеих команд и использовать их для исследования всего спектра доступных возможностей.

Рис. 14-8. Использование sed для замены текста.
В дополнение к sed для обработки вывода можно использовать awk. Как и sed, команда awk может принимать вывод другой команды в качестве стандартного ввода и обрабатывать его заданным образом. Однако способ работы awk несколько отличается. Команда awk рассматривает каждую строку получаемого текста как запись (record). Каждое слово в строке, разделённое пробелом или символом табуляции, считается отдельным полем (field) внутри записи.
Например, рассмотрим следующий текстовый файл:
Lorem ipsum dolor sit amet, consectetur adipisicing elit,
sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in
reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia
deserunt mollit anim id est laborum
По мнению awk, в этом файле семь записей, так как он содержит семь отдельных строк текста. Каждая строка заканчивается символом возврата каретки/перевода строки, образующим новую строку. Именно этот символ awk использует для определения конца записи. Первая запись содержит восемь полей, вторая — одиннадцать и так далее. Это показано в таблице 14-1.
| Запись | Поле1 | Поле2 | Поле3 | Поле4 | Поле5 | Поле6 | Поле7 | Поле8 | Поле9 | Поле10 | Поле11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Lorem | ipsum | dolor | sit | amet, | consectetur | adipisicing | elit, | |||
| 2 | sed | do | eiusmod | tempor | incididunt | ut | labore | et | dolore | magna | aliqua. |
Таблица 14-1. Просмотр текстового файла как базы данных.
Обратите внимание, что разделителем полей служит пробельный символ, а не пунктуация. Каждое поле обозначается как $номер_поля. Например, первое поле любой записи обозначается как $1, второе — $2 и так далее.
С помощью awk можно указать поле в конкретной записи и обработать его определённым образом. Синтаксис команды awk: awk 'шаблон {обработка}'. Например, можно ввести cat lipsum2.txt | awk '{print $1,$2,$3}' для вывода первых трёх слов («полей») каждой строки («записей»). Поскольку шаблон для поиска не задан, awk просто выводит первые три слова каждой строки. Это показано на рис. 14-9.

Рис. 14-9. Использование awk для вывода первых трёх полей каждой записи.
Можно также задать шаблон для точного указания записей, по которым выполняется поиск. Например, предположим, что необходимо вывести первые три поля только тех записей, которые содержат где-либо в строке текст «do». Для этого к команде добавляется шаблон /do/. Это показано на рис. 14-10.
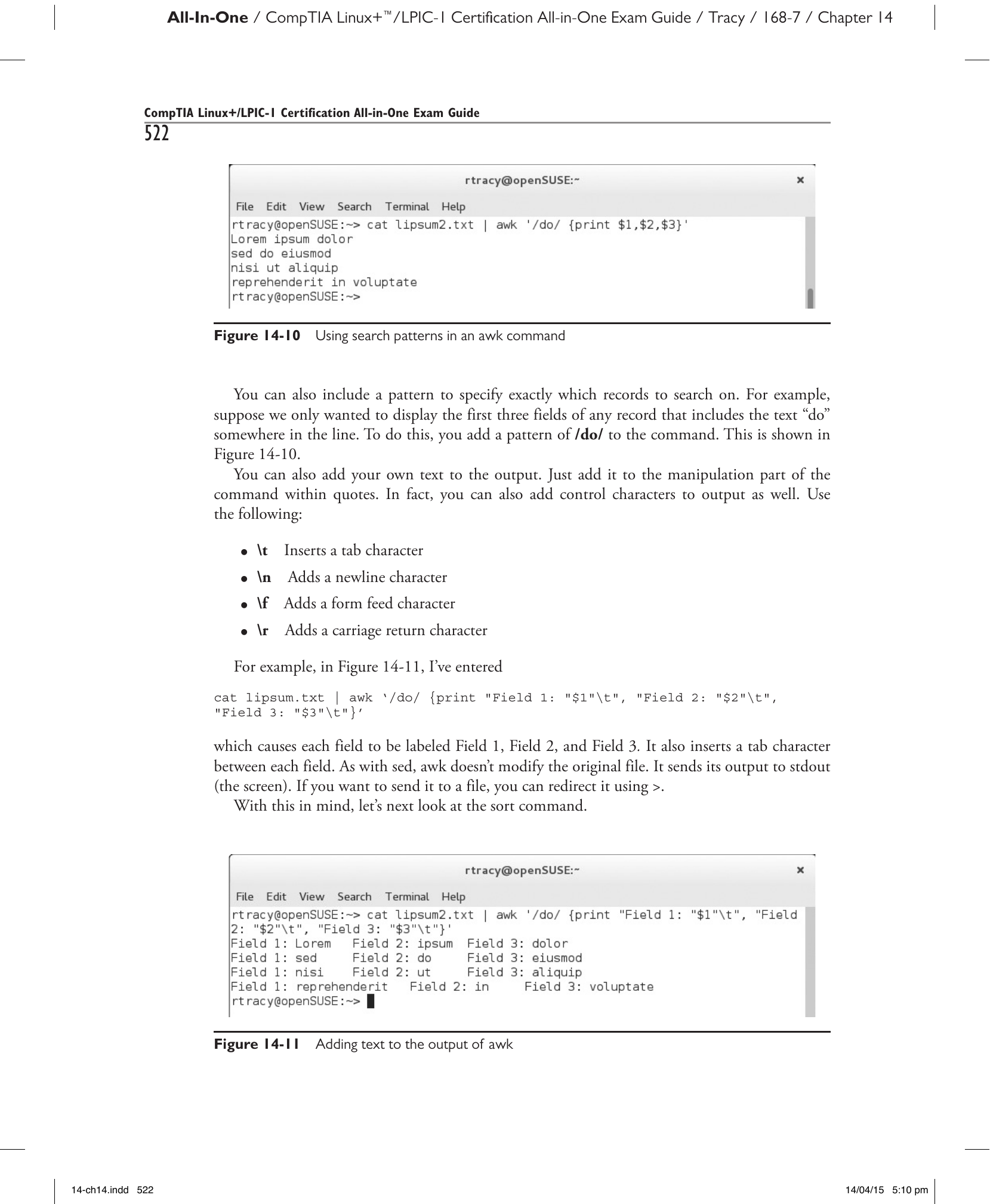
Рис. 14-10. Использование шаблонов поиска в команде awk.
Можно также добавлять собственный текст в вывод: достаточно указать его в кавычках внутри части команды, отвечающей за обработку. Более того, в вывод можно добавлять и управляющие символы. Используйте следующие обозначения:
\t— Вставить символ табуляции.\n— Добавить символ перевода строки.\f— Добавить символ перевода страницы.\r— Добавить символ возврата каретки.
Например, на рис. 14-11 введена следующая команда:
В результате каждому полю присваивается метка «Field 1», «Field 2», «Field 3», а между полями вставляется символ табуляции. Как и sed, команда awk не изменяет исходный файл. Вывод направляется на стандартный вывод (экран). Для записи вывода в файл можно перенаправить его с помощью >.
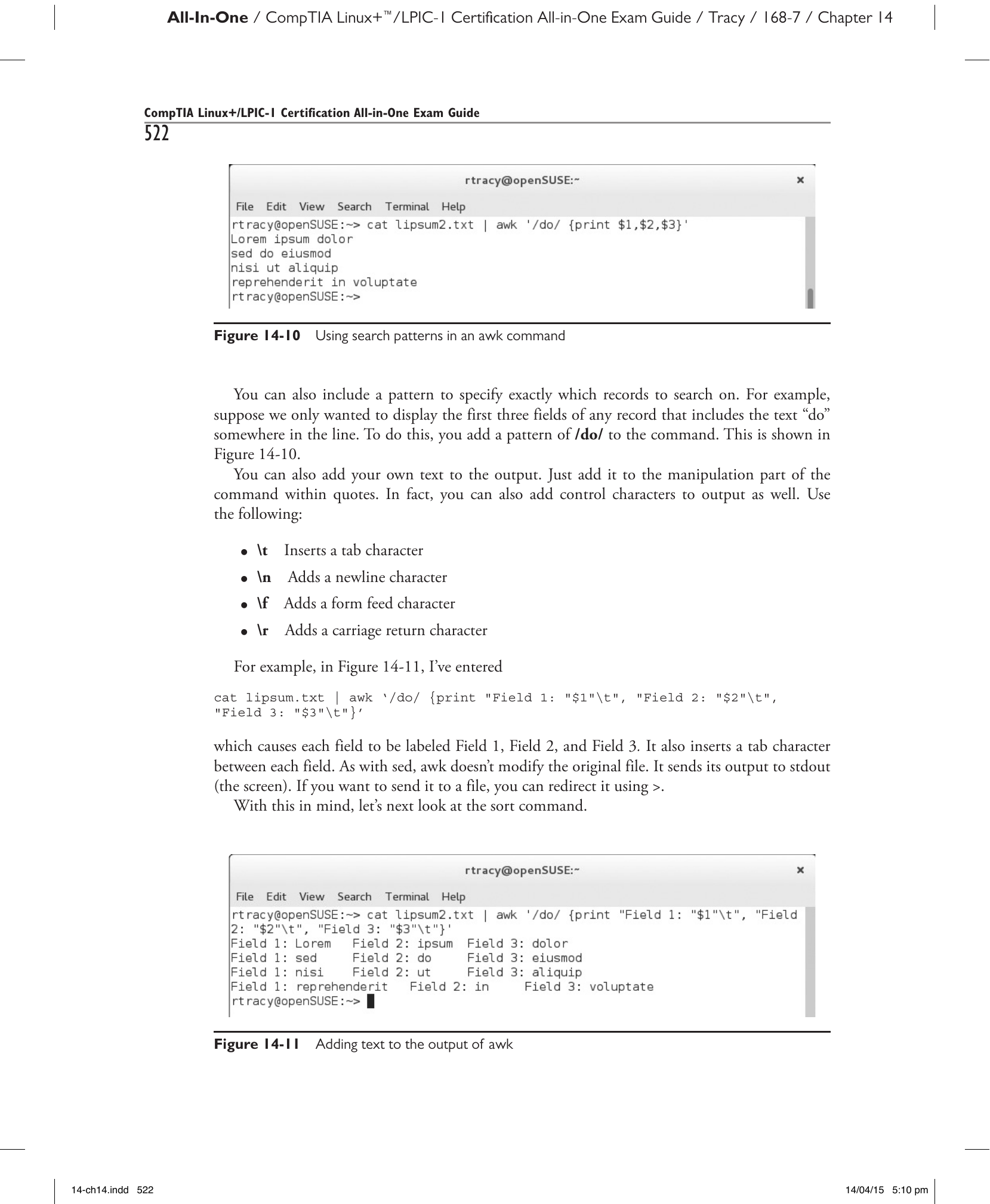
Рис. 14-11. Добавление текста в вывод команды awk.
Рассмотрим далее команду sort.
sort¶
Команда sort сортирует строки текстового файла в алфавитном порядке. Вывод направляется на стандартный вывод. Среди наиболее часто используемых параметров команды sort выделим следующие:
-f— Привести строчные символы к верхнему регистру перед сортировкой.-M— Сортировать по месяцу.-n— Сортировать в числовом порядке.-r— Обратить порядок сортировки.
Например, команда sort -n -r firstnames сортирует строки файла firstnames в обратном числовом порядке. Пример показан ниже:
Команда sort может применяться для сортировки вывода других команд (например, ps) путём передачи стандартного вывода первой команды на стандартный ввод команды sort.
Рассмотрим далее команду split.
split¶
Команда split разбивает входной файл на серию файлов (без изменения исходного файла). По умолчанию входной файл разбивается на сегменты по 1000 строк. Для указания другого числа строк можно использовать параметр -n.
Например, команда split -1 firstnames outputfile_ может быть использована для разбивки файла firstnames на три отдельных файла, каждый из которых содержит одну строку. Это показано на рис. 14-12.

Рис. 14-12. Разбивка файла с помощью split.
Рассмотрим далее команду tr.
tr¶
Команда tr используется для преобразования или удаления символов. Следует учитывать, что эта команда не работает непосредственно с файлами. Для её применения к файлам необходимо сначала использовать, например, команду cat для передачи текстового потока на стандартный ввод команды tr. Синтаксис: tr параметры X Y. Среди наиболее часто используемых параметров команды tr выделим следующие:
-c— Использовать все символы, не входящие в X.-d— Удалить символы, входящие в X; преобразование не выполняется.-s— Заменить каждую входную последовательность повторяющегося символа из X одним вхождением этого символа.-t— Предварительно усечь X до длины Y.
Например, для преобразования всех строчных символов в файле lastnames в символы верхнего регистра можно ввести cat lastnames | tr a-z A-Z:
Рассмотрим далее команду uniq.
uniq¶
Команда uniq выводит или пропускает повторяющиеся строки. Синтаксис: uniq параметры входной_файл выходной_файл. С командой uniq можно использовать следующие параметры:
-d— Выводить только повторяющиеся строки.-u— Выводить только уникальные строки.
Например, предположим, что файл lastnames содержит дублирующиеся записи:
С помощью команды uniq lastnames можно удалить повторяющиеся строки. Пример показан ниже:
Следует учитывать, что команда uniq работает только в том случае, если повторяющиеся строки являются смежными. Если текстовый поток содержит повторяющиеся строки, которые не являются смежными, можно сначала использовать команду sort, чтобы сделать их смежными, а затем передать вывод на стандартный ввод команды uniq.
Рассмотрим наконец команду wc.
wc¶
Команда wc выводит количество символов новой строки, слов и байтов в файле. Синтаксис: wc параметры файлы. С командой wc можно использовать следующие параметры:
-c— Вывести количество байтов.-m— Вывести количество символов.-l— Вывести количество символов новой строки.-L— Вывести длину самой длинной строки.-w— Вывести количество слов.
Например, для вывода всех счётчиков и итогов для файла firstnames следует использовать команду wc firstnames:
Попрактикуемся в обработке текстовых потоков в следующем упражнении.
Упражнение 14-2. Обработка текстовых потоков
В этом упражнении вы будете практиковаться в обработке текстовых потоков. Упражнение можно выполнить на виртуальной машине, прилагаемой к книге. Для получения правильно настроенной среды запустите снимок 14-2.
Видео
Посмотрите видеозапись упражнения 14-2 с демонстрацией выполнения данного задания.
Выполните следующие шаги:
- При необходимости загрузите систему Linux и войдите в систему как обычный пользователь.
-
В командной строке убедитесь, что в вашем домашнем каталоге существует файл
test.txt, введя командуls.Этот файл содержит следующий текст:
-
Используйте
sedдля замены слова «oportere» словом «democritum» и отправьте вывод в новый файл с именемtestsed.txt: a. В командной строке введитеcat ~/test.txt | sed s/oportere/democritum/ 1>testsed.txt. b. С помощью командыcatубедитесь, что слово было заменено в файлеtestsed.txt. - Используйте
awkдля вывода второго слова в каждой строке файлаtest.txt, содержащей символы «us». Введите в командной строкеcat ~/test.txt | awk '/us/ {print $2}'. - Какая строка совпала и какое слово в результате было выведено на экран?